
Recent advances in text-to-image customization have enabled high-fidelity, context-rich generation of personalized images, allowing specific concepts to appear in a variety of scenarios. However, current methods struggle with combining multiple personalized models, often leading to attribute entanglement or requiring separate training to preserve concept distinctiveness. We present LoRACLR, a novel approach for multi-concept image generation that merges multiple LoRA models, each fine-tuned for a distinct concept, into a single, unified model without additional individual fine-tuning. LoRACLR uses a contrastive objective to align and merge the weight spaces of these models, ensuring compatibility while minimizing interference. By enforcing distinct yet cohesive representations for each concept, LoRACLR enables efficient, scalable model composition for high-quality, multi-concept image synthesis. Our results highlight the effectiveness of LoRACLR in accurately merging multiple concepts, advancing the capabilities of personalized image generation.
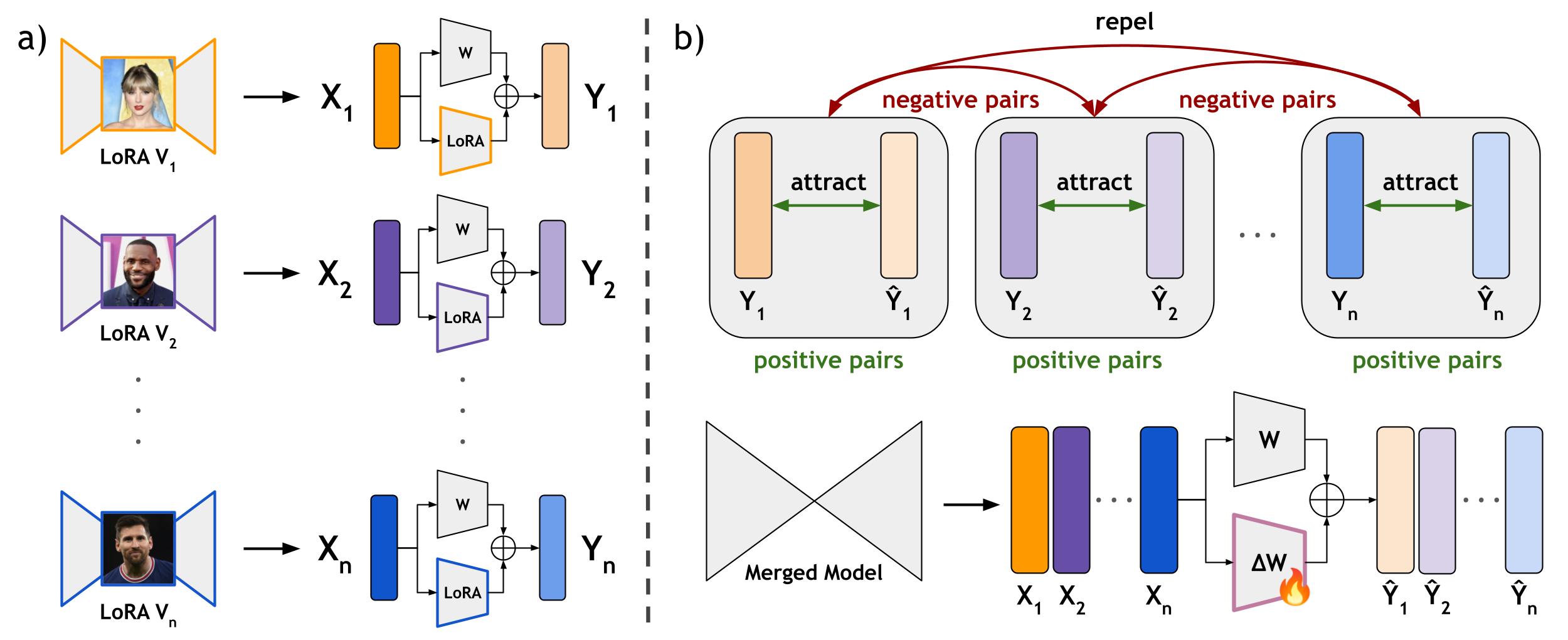
Framework Overview. The framework comprises two main stages: (a) generating concept-specific representations with individual pre-trained LoRA models and (b) merging these representations into a unified model using a novel contrastive objective. In (a), each LoRA model produces input-output pairs (Xi, Yi) for distinct concepts (V1, V2, …, Vn), establishing positive pairs (aligned concepts) and negative pairs (unrelated concepts). In (b), these representations are combined into a single model, ΔW, to enable multi-concept synthesis. LoRACLR aligns attracting positive pairs to ensure identity retention and repelling negative pairs to prevent cross-concept interference.

Qualitative Results. LoRACLR effectively combines different numbers of unique concepts across a wide range of scenes, producing high-fidelity compositions that capture the complexity and nuance of multi-concept prompts in diverse environments. LoRACLR preserves the identity of each concept, ensuring accurate representation in composite scenes while also maintaining fidelity in single-concept generation, as demonstrated in the last row. Real images from the original concepts are shown on the left for reference.
Non-Human Subject Generation. Our method effectively combines diverse concepts such as animals, objects (e.g., tables, chairs, vases), and monuments (e.g., pyramids, rocks) into cohesive and visually appealing scenes.





Style LoRA Integration. Our method integrates diverse styles, such as comic art and oil painting, into multi-subject compositions, maintaining high stylistic fidelity and content coherence. Examples include scenes in comic art and oil painting styles, highlighting the flexibility of our approach.
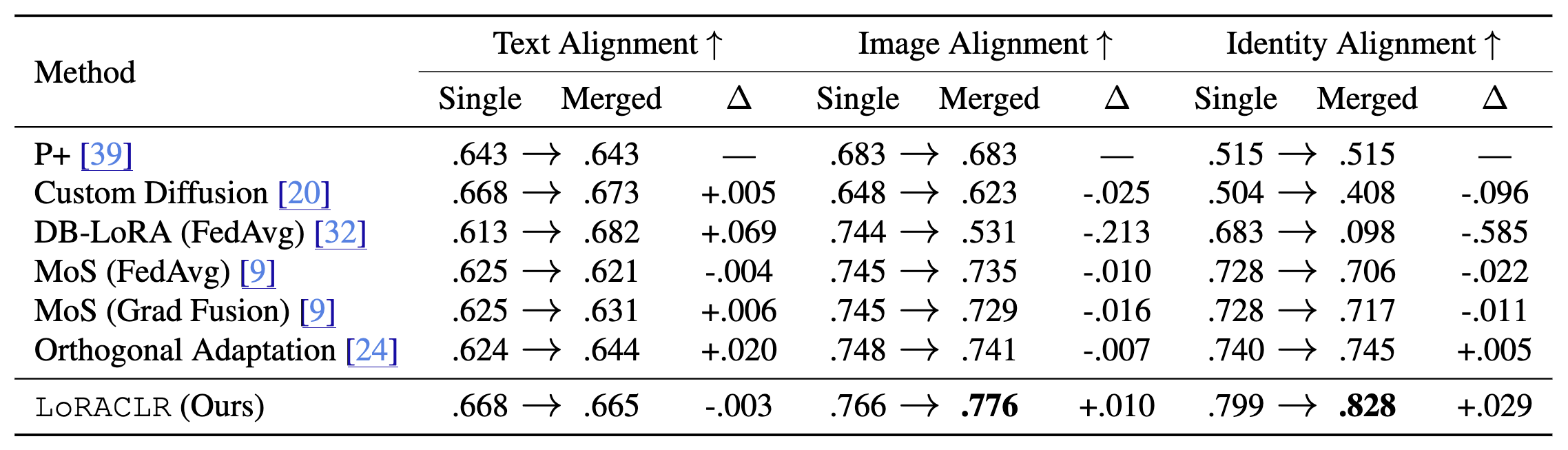
Quantitative Results. Comparison of LoRACLR against state-of-the-art models, evaluated before and after merging. LoRACLR achieves competitive performance across all metrics, with notable improvements in image and identity alignment post-merging.

Quantitative Results on Number of Concepts. Text alignment, image alignment, and identity preservation scores as the number of merged concepts increases. Our method achieves high scores across all metrics, maintaining identity and prompt adherence. Dots represent the baseline metrics for each LoRA model before merging, serving as a reference for performance comparisons.
Our method provides a powerful tool for merging pre-trained LoRA models to enable multi-subject image synthesis. This capability has the potential to significantly enhance creative expression, improve personalized image generation, and address limitations in existing image synthesis methods. By leveraging LoRA models, which can be fine-tuned on specific concepts, our approach ensures results that are coherent and adaptable to diverse needs.
Unlike prior approaches that rely on generic, biased datasets for facial priors, our method can integrate personalized priors, ensuring that results are more faithful and accurate to an individual’s identity. This feature is particularly valuable for underrepresented groups, as it mitigates biases inherent in large, generic datasets and ensures high-quality, equitable outcomes. By empowering users to create personalized and inclusive image compositions, we aim to enhance satisfaction with synthesized images and promote fairness in image synthesis technologies.
However, these advancements come with ethical considerations. The ability to synthesize novel images through LoRA model composition introduces risks of misuse, such as creating deepfakes or misleading content. While our approach requires access to well-trained LoRA models and thus sets a barrier to entry for malicious actors, the potential for harm cannot be ignored. Moreover, research suggests that deep-generated images are still detectable as synthetic, reducing the risk of widespread misuse at scale. Nevertheless, we emphasize the importance of deploying our method responsibly and call for continued research into ethical safeguards and detection mechanisms in generative modeling. By fostering a culture of responsible innovation, we aim to ensure that our advancements contribute positively to society.
@InProceedings{Simsar_2025_CVPR,
author = {Simsar, Enis and Hofmann, Thomas and Tombari, Federico and Yanardag, Pinar},
title = {LoRACLR: Contrastive Adaptation for Customization of Diffusion Models},
booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)},
month = {June},
year = {2025},
pages = {13189-13198}
}